On June 29, 2026, Meta's AI lab released the first Brain2Qwerty model, which was published in Nature Neuroscience, and Brain2Qwerty v2, which was made public. Both decode text from brain activity recorded entirely outside the head. Jarod Levy, first author on the v1 paper, framed the point directly, saying that the aim is to "decode language from brain activity without surgery," with what the team calls "unprecedented performance for a non-invasive MEG setup." The work comes out of Meta's Brain and AI team, led by Jean-Rémi King.
The number that carried the announcement was 61% word accuracy. It sounds modest until you compare it to the prior art, where earlier non-invasive brain-to-text systems hovered around 8%.

MEG
Brain2Qwerty reads magnetoencephalography. MEG measures the weak magnetic fields thrown off by the brain's electrical activity, using sensors arranged in a helmet that sits on the head. It is not an EEG, which reads electrical potentials at the scalp and smears them on the way out, and it is not an implant. The signal is cleaner than EEG, which is why it is sufficient to detect the motor planning underlying finger movements.
The recordings came from healthy volunteers at the Basque Center on Cognition, Brain and Language, typing short memorized sentences in Spanish on an ordinary QWERTY keyboard while the scanner monitored the motor cortex at work.
How it works
The version in Nature Neuroscience, v1, was a three-stage network. A convolutional front module with spatial attention read the raw channels, a transformer put them in context, and a language model cleaned up the output. It worked, and MEG clearly outperformed EEG, but it had two constraints: it required knowledge of when each keypress occurred, and it was not real-time. On MEG, it reached a character error rate of about 29%, and closer to 18% for the best participants.
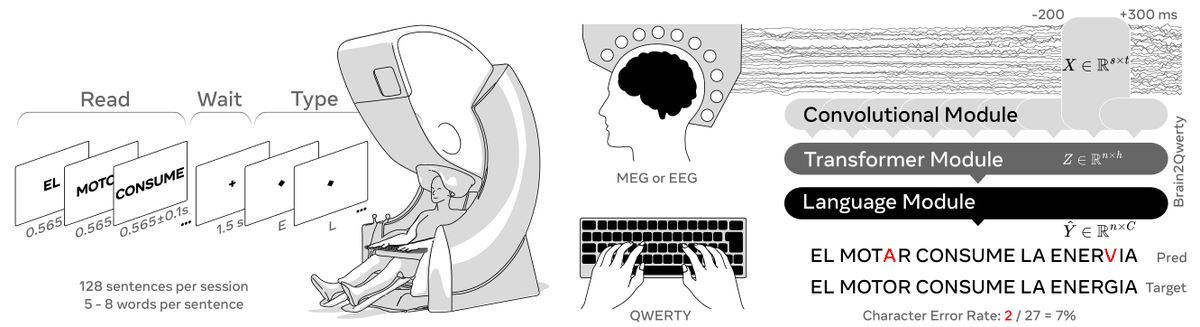
v2 drops the training wheels. It runs end-to-end on continuous raw MEG with no keystroke timing, decoding letters, then words, then whole sentences. A Conformer processes the signal, an aligner maps neural activity to language units, and a fine-tuned large language model turns noisy predictions into fluent text. One of the clearer outside summaries, from Aaryan Kakad, put the mechanism plainly: "The signal supplies the rough shape; the LLM supplies fluency." That division of labour is the design.
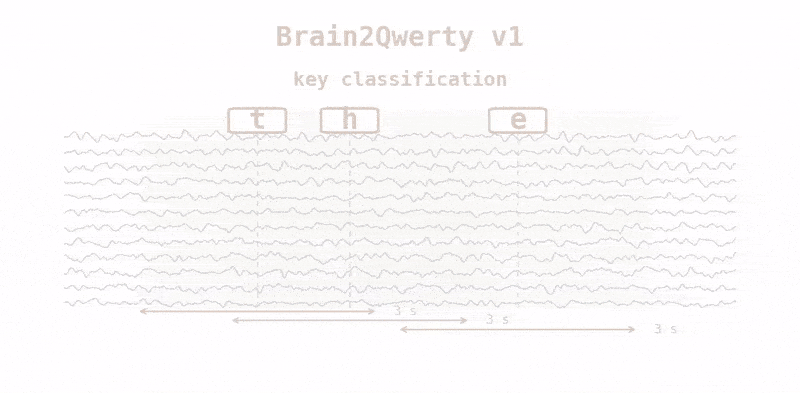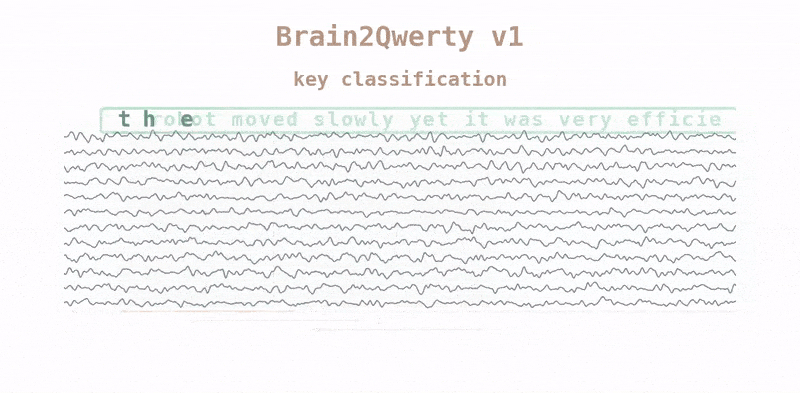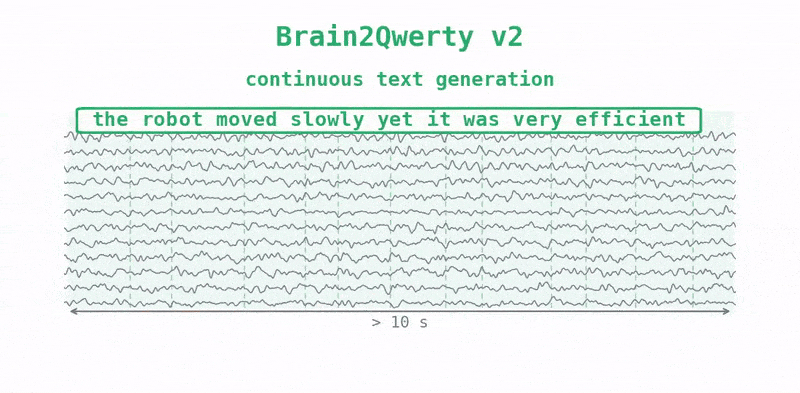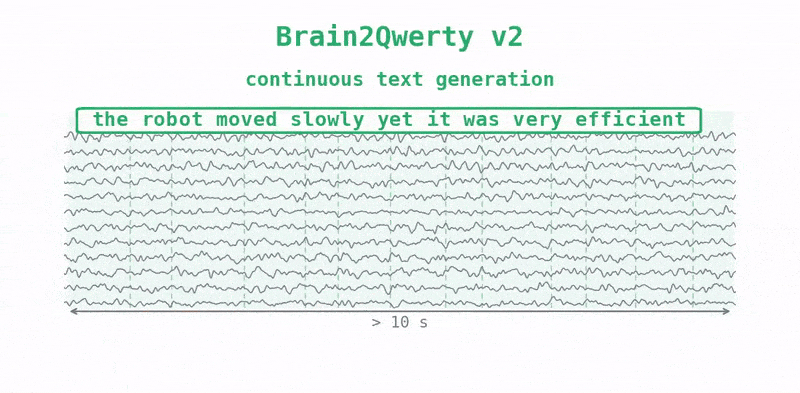
The other change was scale. Meta's team trained v2 on "~22,000 sentences from 9 volunteers, each recorded for 10 hours wearing an MEG device while typing," roughly ten times the data per person that v1 had.
The results
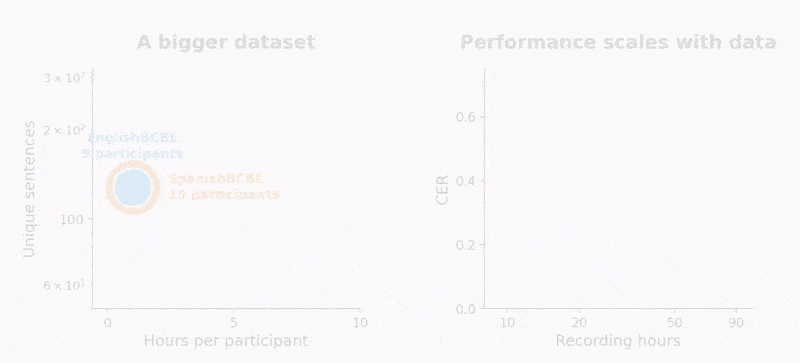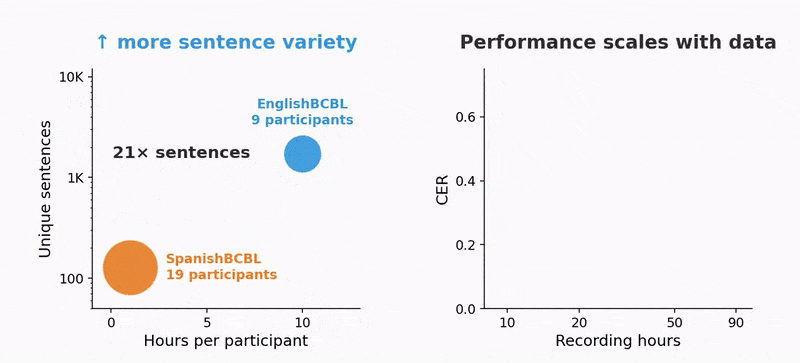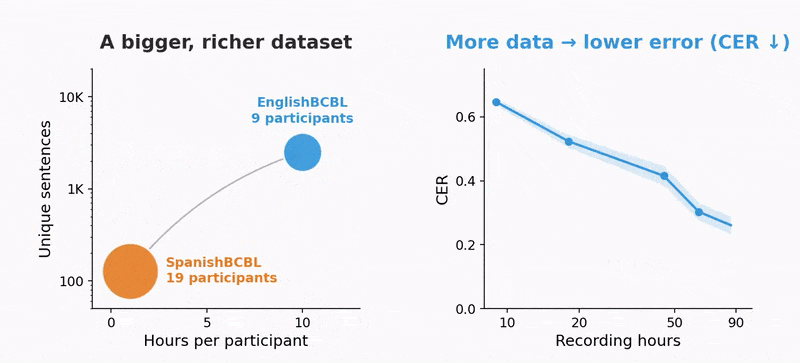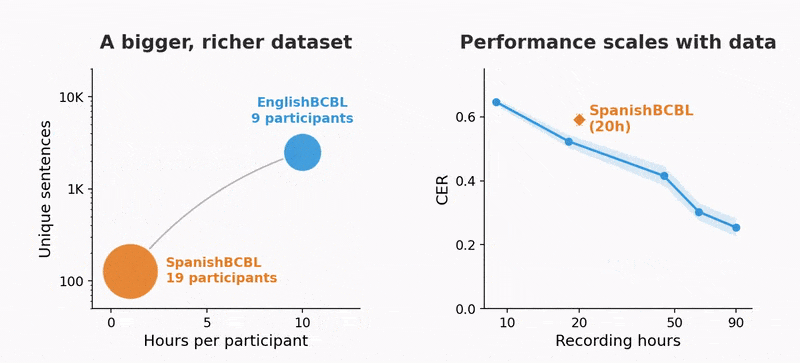
Across participants, v2 averaged 61% word accuracy. The best participant reached 78%, and for that person, more than half of the decoded sentences came out with one word wrong or none. The prior non-invasive baseline was around 8%, so this is close to an order-of-magnitude jump. The more telling result is the shape of the curve. Accuracy rose log-linearly with the amount of training data, and the team says it has not seen a plateau. "Performance scales log-linearly with data volume," in their words, which is a claim that the gap with invasive implants might be closed by collecting more data rather than inventing a new model.
The hardware
Here is the part that keeps this in the lab. MEG runs on a research-grade scanner, with systems from makers like Megin, sitting in a magnetically shielded room. The machine is large, expensive, and immobile, and the person has to keep their head inside it. Every accuracy number above carries that asterisk. The team is adamant that this is the limiting factor and points to work on wearable MEG sensors as the way out. Until that arrives, this is a decoder that needs a building, not a headset.
What the research shows
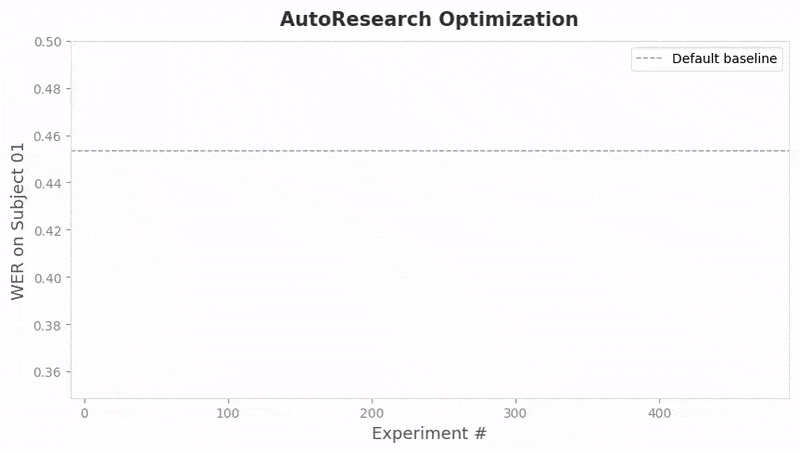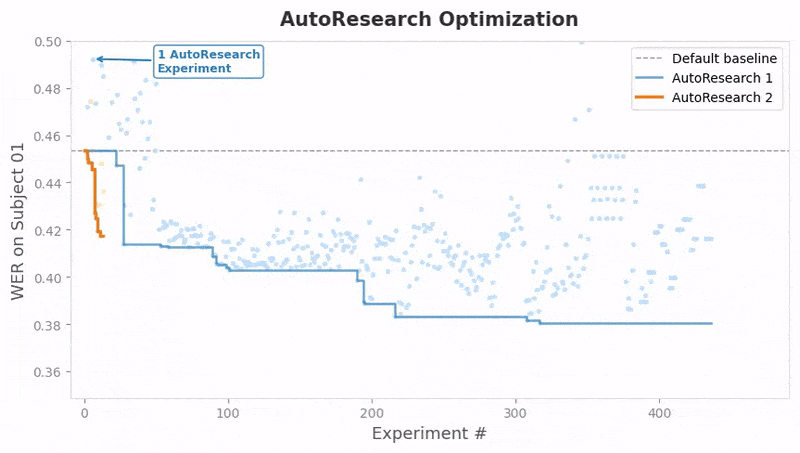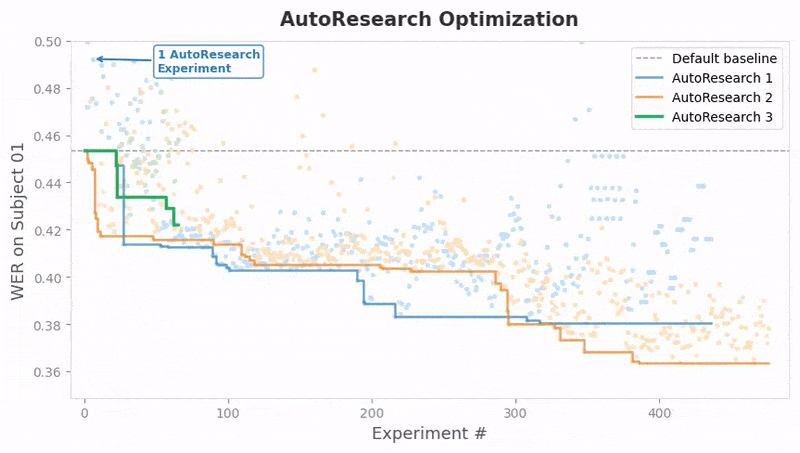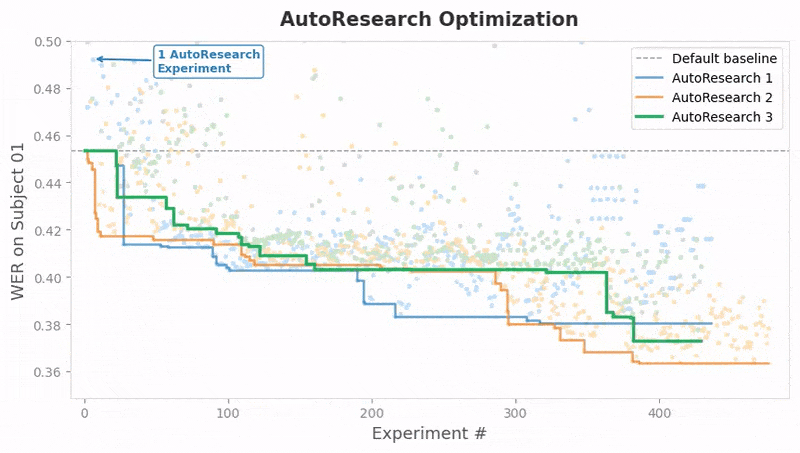
The team also leaned on autonomous AI coding agents to optimize the pipeline and push performance further. The agents independently discovered hyperparameter strategies and optimizations that generalized successfully across all 9 subjects.
A few things stand out beyond the headline number. End-to-end learning on the raw signal beats hand-built feature pipelines, the same lesson the rest of deep learning has taught elsewhere. The language model is not a cosmetic finish. It does real work, turning ambiguous neural output into sentences by leaning on what it knows about language. And the signal the system reads is motor. The volunteers were typing, not silently imagining words, so the brain activity is the planning and execution of finger movements. That matters because the people this is meant to help often cannot move, and decoding imagined movement is a harder and less proven problem. Open-sourcing is the lever the team is betting on: code for both versions and, from their partner BCBL, the v1 dataset, along with a benchmark they call NeuralBench.
The reaction
The science drew both a wary response and, often, a similar one. Most people latched onto the prospect of giving speech back to people with ALS, stroke, or locked-in syndrome. Some read it as a genre shift. As Adel Bucetta put it, "most AI research still isn't about building something people use, but more about figuring out what's possible. brain2qwerty might just be one of the first to close that gap." Others reached for the obvious jokes. "The keyboard is becoming a fossil," wrote Tommy T. Someone else labelled it the "Thoughtcrime Machine 9000," and more than one person invoked Professor X.
The anxiety was concentrated on one fact: this is Meta. "This being done by the most privacy-invasive corporation in the world is genuinely crazy," ran one reply. Another made the sharper point that "mental privacy is the ultimate form of privacy a person could possess." The concern is not really about Brain2Qwerty, which needs a shielded room and a cooperative subject typing on a keyboard. It is about where a working version of this points, and who is holding it.
What it means
The model got dramatically better, and the hardware did not. Meta narrowed the gap with invasive interfaces in terms of accuracy while keeping the overall approach non-invasive, which is the trade-off the field has wanted. The motivation is not in doubt.
We believe this research has the potential to make a real difference for the millions of people who suffer from brain lesions or disorders that prevent them from communicating.
Getting there depends on things this release does not solve: a wearable sensor, decoding for people who cannot type, and robustness outside a quiet room. The scaling curve is the reason for optimism. If accuracy really does keep climbing with data, the open datasets make that a problem the whole field can chip at. That is the part to watch.
References
- Project page, code and models: facebookresearch.github.io/brain2qwerty
- Meta AI: ai.meta.com
- Announcement, Jean-Rémi King: x.com/JeanRemiKing
- Jarod Levy: x.com/JarodLevy
- AI at Meta: x.com/AIatMeta